/flume/events
Flume, HDFS, Hive, PrestoDB
This section describes architecture for capturing clickstream events, passing them directly to HDFS, defining Hive table working on the data from HDFS file structure and using PrestoDB for faster SQL queries.
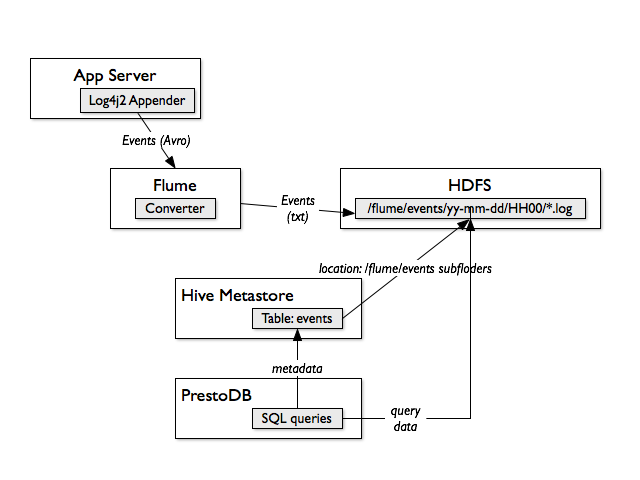
Application server (client application) is a source of events. Collected events are logged with Log4J Appender to Apache Flume. Log4j appender uses Avro data format and establishes communication channel with Flume’s agent. The communication between log4j and Flume is event driven.
Flume is able to append events to file in Hadoop and also is able to apply a converters/interceptors on the fly before sending the events to HDFS.
The HDFS (Hadoop Distributed File System) is so called sink for Flume. The events are appended to files in strictly defined hierarchy of folders.
The root folder
Rolled subfolders by date
/flume/events/yy-mm-dd /flume/events/16-02-18 /flume/events/16-02-19
Rolled subfolder by hour
/flume/events/yy-mm-dd/HH00 /flume/events/16-02-18/0700 /flume/events/16-02-18/0800 /flume/events/16-02-18/0900
Apache Hive data warehouse is used mainly as a metadata reference store. The tables are defined in Hive but all the SQL queries are executed with PrestoDB.
Hive tables are defined as external what gives us ability to keep log files in place in /flume/events folder. This approach has one more advantage. We can recreate Hive tables anytime, without data lose or data migration.
In runtime only Hive Metastore is required.
PrestoDB distributed SQL query engine is used for faster execution of SQL queries. It is configured to use Hive catalog (connected to Hive Metastore).
Configuration
This section covers configuration options important only from the presented architecture point of view. The rest of options is configured as described in products' documentation.
Event source application server
The application has to have log4j flume appender jar included on the classpath.
Example of Gradle dependencies
// log4j2 dependenies
// lmax is required for asynchronous logging
runtime "org.apache.logging.log4j:log4j-slf4j-impl:2.4.1"
runtime "org.apache.logging.log4j:log4j-api:2.4.1"
runtime "org.apache.logging.log4j:log4j-core:2.4.1"
runtime "com.lmax:disruptor:3.3.2"
// log4j flume dependency
runtime "org.apache.logging.log4j:log4j-flume-ng:2.5"All configuration parameters are described in appender documentation. It is able to work as a remote Flume client, as an embeeded Flume agent or as an async publisher with persistent storage for events. The first mode is the simplest to configure but its downside is that once Flume server is not accessible it throws exceptions and the events could be lost.
Flume
Configuration file: conf/flume-conf.properties.
Flume defines so called agents. Every agent is composed out of source, channel and sinks. In our case we define one Avro Source, one Memory Channel and two sinks, the HDFS Sink and File Roll Sink (mainly for debugging purposes).
Example configuration
agent.sources=s1 agent.channels=c1 agent.sinks=hdfs1 log1 agent.sources.s1.type=avro agent.sources.s1.bind=FLUME_HOST agent.sources.s1.port=1414 agent.sources.s1.channels=c1 agent.sinks.hdfs1.type=hdfs agent.sinks.hdfs1.hdfs.path=hdfs://HDFS_CLUSTER/flume/events/%y-%m-%d/%H00 agent.sinks.hdfs1.hdfs.filePrefix=events agent.sinks.hdfs1.hdfs.fileSuffix=.log agent.sinks.hdfs1.hdfs.fileType=DataStream agent.sinks.hdfs1.hdfs.writeFormat=text agent.sinks.hdfs1.hdfs.useLocalTimeStamp=true agent.sinks.hdfs1.hdfs.rollInterval=300 agent.sinks.hdfs1.hdfs.rollSize=0 agent.sinks.hdfs1.hdfs.rollCount=0 agent.sinks.hdfs1.hdfs.round=true agent.sinks.hdfs1.hdfs.roundValue=60 agent.sinks.hdfs1.hdfs.roundUnit=minutes agent.sinks.hdfs1.channel=c1 agent.sinks.log1.type=file_roll agent.sinks.log1.sink.directory=DIR agent.sinks.log1.sink.rollInterval=0 agent.sinks.log1.channel=c1 agent.channels.c1.type=memory agent.channels.c1.capacity=1000 agent.channels.c1.transactionCapacity=100
Input Avro source is bounded to the host where Flume is installed. Default port 1414 is used.
HDFS sink has defined path for storing events as HDFS folder with dynamically created subfolders. The round, roundValue and roundUnit attributes define when new folder for hours and folder for day are created.
If Flume is installed on the machine where HDFS name node is installed it can point directly to the name of the HDFS cluster. Then High Availability properties are automatically used.
The rollInterval setting, that is set to 300 seconds, forces to roll files with logs after 5 minutes. It means that the data is visible in Hive tables with max 5 minutes delay.
Command to start Flume server
$ nohup bin/flume-ng agent -n agent -c conf -f conf/flume-conf.properties & echo $! > PID $ netstat -anp | grep 1414
Hive
Configuration file: conf/hive-site.xml
|
Important
|
set the same number of max replications in mapreduce-site.xml and hdfs-site.xml
|
- $HADOOP_INSTALL/conf/hdfs-site.xml
-
-
dfs.replication.min=2
-
dfs.replicattion=2
-
dfs.replication.max=6
-
- $HADOOP_INSTALL/conf/mapred-site.xml
-
-
mapreduce.client.submit.file.replication=6
-
If not set properly the following exception should be thrown while submitting mapreduce job:
org.apache.hadoop.ipc.RemoteException(java.io.IOException): file .../map.xml. +
Requested replication 10 exceeds maximum 6|
Important
|
if there are additional libraries included in HADOOP installation in $HADOOP_INSTALL/lib, like LZO codecs then they have to be included in Hive classpath too.
|
- conf/hive-env.sh
-
-
export HIVE_AUX_JARS_PARH=$HADOOP_INSTALL/lib
-
If LZO compression codec is included in distribution:
- $HADOOP_INSTALL/conf/mapred-site.xml
-
-
mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec
-
mapred.child.env=JAVA_LIBRARY_PATH=$JAVA_LIBRARY_PATH:$HADOOP_INSTALL/lib/native-lzo
-
Without these settings the following exception may be thrown:
java.lang.ClassNotFoundException: Class com.hadoop.compression.lzo.LzoCodec not found|
Important
|
when mapreduce job throws Java Heap Space Error, change Java settings. |
- $HADOOP_INSTALL/conf.mapred-site.xml
-
-
mapred.child.java.opts=-Xmx2G
-
mapreduce.map.memory.mb=4096
-
mapreduce.reduce.memory.mb=5120
-
mapreduce.task.io.sort.mb=1024
-
|
Important
|
in order to use subfolders in Hive tables definitions as LOCATION parameter.
|
Without these settings it is not possible to define root folder as a Hive table LOCATION '/flume/events'.
- conf/hive-site.xml
-
-
mapred.input.dir.recursive=true
-
hive.mapred.supports.subdirectories=true
-
|
Important
|
start metastore and hiveserver2 as separate processes. |
Only then more than one application process is able to connect to Hive’s Metastore.
- conf/hive-site.xml
-
-
hive.metastore.uris=thrift://HIVE_HOST:9083
-
|
Important
|
change Hive metadata location in HDFS |
- conf/hive-site.xml
-
-
hive.metastore.warehouse.dir=/hive/warehouse
-
Command to start Hive Metastore:
$ nohup bin/hive --service metastore & echo $! > PID_MS
Command to start Hiveserver2:
$nohup bin/hive --service hiveserver2 & echo $! > PID_HS2
Command to start Hive shell: as user hadoop
$ bin/beeline -n hadoop -u jdbc:hive2://HIVE_HOST:10000
PrestoDB
While configuring PrestoDB we can encounter almost the same issues like with Hive.
|
Important
|
if there are additional libraries in HADOOP installation copy them to Presto classpath. |
In PrestoDB there is not possible (I couldn’t find any setting) to point additional path to its classpath. So all libraries (jars) from $HADOOP_INSTALL/lib has to be coppeid.
$ cp $HADOOP_INSTALL/lib* plugin/hive-hadoop2
|
Important
|
in order to use subdirectories of HDFS file system new setting is needed. |
- etc/catalog/hive.properties
-
-
connector-name=hive-hadoop2
-
hive.config.resources=$HADOOP_INSTALL/conf/core-site.xml, $HADOOP_INSTALL/conf/hdfs-site.xml
-
hive.recursive-directories=true
-
Command to start|stop|restart PrestoDB:
$ bin/launcher start|stop|restart|status
PrestoDB command line client
The client requires java installed. Its installation instructions can be found there: PrestoDB Client installation.
Command to start PrestoDB client:
$ bin/presto --server PRESTODB_HOST:8070 --catalog hive --schema default
We assume that etc/config.properties configuration file has changed port number to http-server.http.port=8070.